
AI破译生命!微软蛋白质研究「超级加速器」登上Science
AI破译生命!微软蛋白质研究「超级加速器」登上Science微软「AI for Science」团队推出BioEmu,将蛋白质研究速度提升10万倍!从结构到功能,从折叠到突变,这个开源神器正改变药物研发的未来。
来自主题: AI技术研报
9340 点击 2025-07-24 16:26
 搜索
搜索
微软「AI for Science」团队推出BioEmu,将蛋白质研究速度提升10万倍!从结构到功能,从折叠到突变,这个开源神器正改变药物研发的未来。

职场人苦“做PPT”久矣。

大家好,我是歸藏(guizang),今天给大家带来 Lovart 的正式版一手介绍和体验。Lovart 我们介绍过很多次了,但是每次都会有新东西。 昨晚看到他们的推特,发现发了正式版,就赶紧试了一下。 今天这个设计 Agent 终于变成了一个完全体,而且这次的更新依然非常牛批。

YouTube这周宣布,将为Shorts创作者推出一系列全新的AI功能。最吸引眼球的,是一个可以“照片变视频”的生成式工具。你只需要上传一张相册里的图片,AI 就能把它变成一段六秒的短视频。

Manus为迷茫的AI从业者定义了Agent的产品范式,至此,一场以华人为主角的AI Agent创业热潮,正在席卷全球。

做应用,就像和 AI 聊天一样简单。
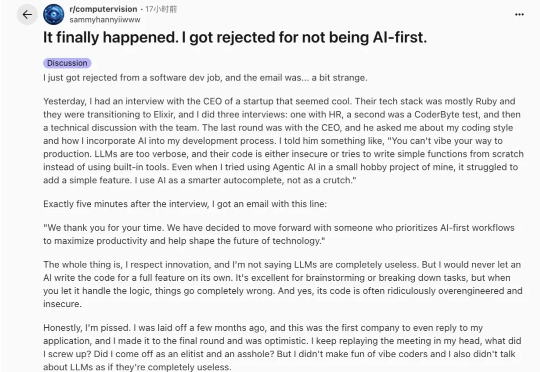
“因为不是AI First,我在终面挂了。” 最近,一外国小哥的经历意外火了! 他表示自己几个月前被解雇,终于来到了一家自己本来很看好的初创公司,并且走到了终面,与CEO面对面。

最近一周,AI Coding产品简直如同井喷。
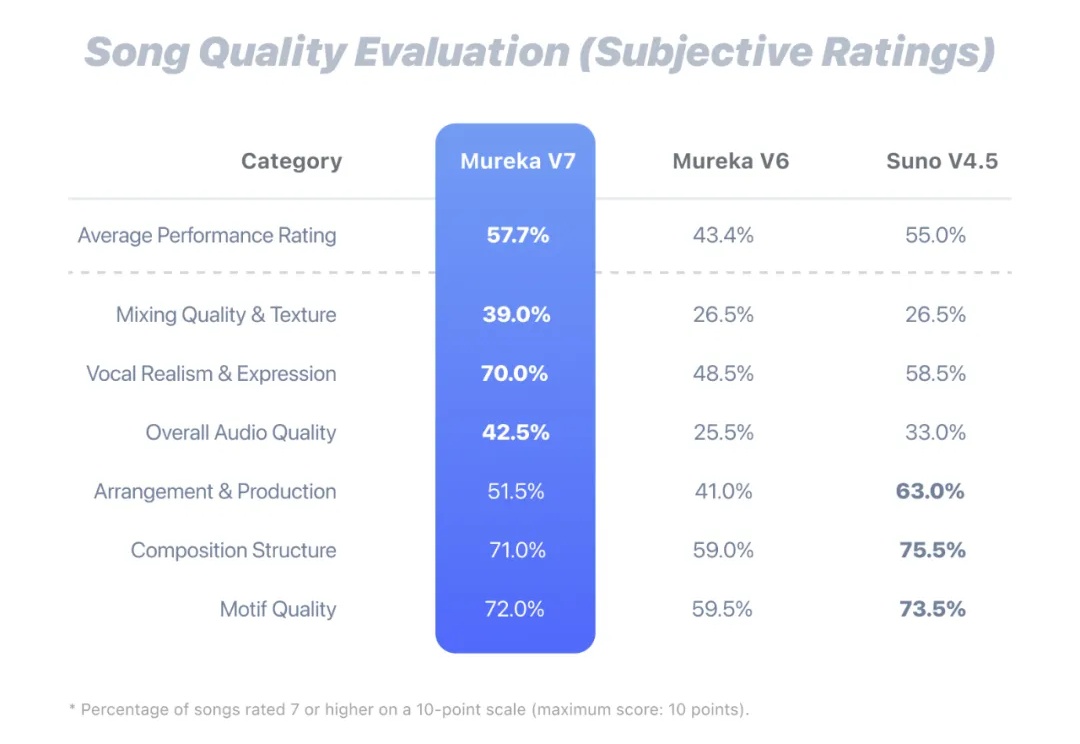
AI 正悄悄「攻占」你的歌单。

“是阿里 AI to C 战略的延展。”